 KAI LAB
KAI LABDetecting SMS Fraud in Chichewa Using Machine Learning: A Research Journey
SSMS fraud, also known as smishing, is a growing global cybercrime where fraudsters exploit mobile users via deceptive text messages to steal sensitive information or money. In African contexts, the challenges are particularly pronounced due to the multilingual environment, frequent code-switching, and a lack of labelled datasets in local languages such as Chichewa. Additionally, the limited availability of linguistic tools and resources further complicates efforts to develop robust detection mechanisms. My early work began with my undergraduate thesis, where I and a colleague collected SMS messages in Chichewa and run machine learning experiments on it. This application was designed to detect and filter fraudulent messages in Chichewa. While the project was promising, gaps in data quality and methodology were identified. The initial dataset, though valuable, needed improvement in terms of size, structure, and diversity, as well as corrections to the methodological approach. Collaboration with Dr. Amelia Taylor allowed for a deep exploration. Sharing a mutual interest in SMS fraud detection, I joined Dr. Taylor to expand the scope of the original project. This collaboration aimed to address critical gaps, including improving the dataset, refining the methodology, and developing a more scalable and accurate detection system tailored for the African context. The expanded research involved several key activities: (1) cleaning and organising the existing dataset from your undergraduate project, (2) collecting new SMS data in Chichewa to create a larger, more representative dataset, (3) refining the methodology to include translation into English to facilitate multilingual model training, and (4) rerunning and improving machine learning experiments to achieve higher accuracy and better generalisation.
This project involved several individuals at the lab, each contributing complementary skills. These included Tamanda Phiri, who was part of the translation team alongside Ben Chapuma and myself. In addition to our roles in translation, Tamanda, Ben and I were actively involved in new data collection efforts which also included Alinafe Lipenga. Dr. Taylor guided us on methodology for machine learning, dataset preparation and data collection.
The inspiration behind the research
Malawi, like many countries, has seen a rise in fraudulent SMS schemes targeting unsuspecting individuals. Several Malawians both in urban and rural areas have fallen victim to this act. A 2023 report from Malawi Communications Regulatory Authority(MACRA) indicated that approximately US$117,000 is stolen every month from Malawians through electronic fraud which usually takes the form of SMS and voice(phone calls). The fraudsters exploit the local language, Chichewa, to reach a wider audience including the rural masses who can read their messages. This Chichewa nature of fraudulent messages makes the traditional fraud detection tools which are often tailored for widely spoken global languages such as English to be less effective. This gap triggered a motivation to explore how machine learning (ML) could be leveraged to address this pressing issue in a local context.
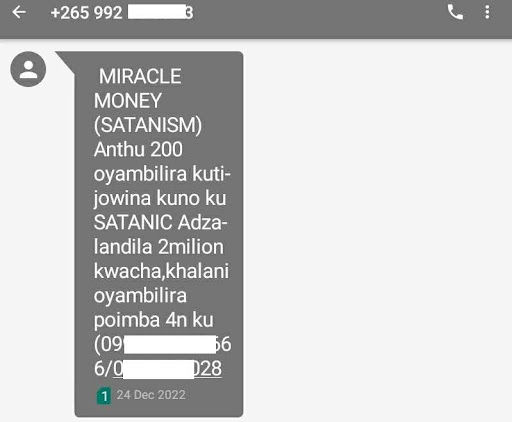
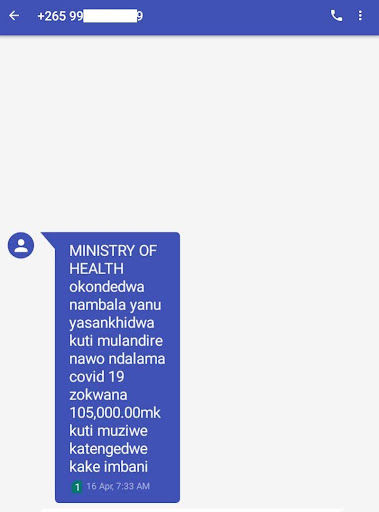
Sample fraudulent SMSs written in Chichewa language
Challenges in working with Chichewa SMS data
One of the first hurdles we faced was the lack of a standardised Chichewa corpus that is suitable for SMSs. Unlike English, where extensive language resources are readily available, Chichewa has limited digital text repositories. There are some Chichewa corpi created for general text: SpokenChichewaCorpus, masakhane-io/lacuna_pos_ner, masakhane-io/masakhane-pos. This scarcity meant we had to get creative with data collection, curating datasets from scratch. We gathered authentic SMS messages, both fraudulent and legitimate, from research participants who had consented and manually annotated them to train our machine learning models.
The role of data augmentation
To enhance our dataset, we employed a manual text augmentation. Chichewa, like other Bantu languages, has rich morphological structures and diverse dialectical variations. By focusing on specific parts of speech such as verbs, pronouns, prepositions, and nouns, we introduced variations in the SMS messages. This process included:
- Addition of words that were implied by the text but were not explicitly present in the original Chichewa SMS.
- Synonym replacement through substitution of words with similar meanings to introduce diversity.
- Replacing borrowed words from English with the equivalent words in vernacular (Chichewa).
Experimenting with machine learning models
Our approach combined natural language processing (NLP) techniques with supervised machine learning algorithms. The preprocessing phase involved tokenising messages, encoding classes and vectorising text using TF-IDF (Term Frequency-Inverse Document Frequency) technique. We trained various models, including logistic regression and random forest, evaluating their performance using accuracy, precision, recall and f1-score metrics.
Insights and outcomes
A subset of 649 messages was used for experimenting with machine learning models. Random Forest model achieved the highest accuracy of 97% while Logistic Regression achieved 96% on Chichewa dataset. Our dataset was also translated by human translators from the research team members and machine translator(Google Translate). From this translated dataset, Logistic Regression achieved highest with 96% accuracy while Random Forest came second with 95%. The performance of both models slightly decreased on the machine translated dataset. Beyond its technical success, the project underscored the importance of developing localized solutions. By tailoring our approach to the nuances of Chichewa, we demonstrated that machine learning can be a powerful tool for addressing language-specific challenges.
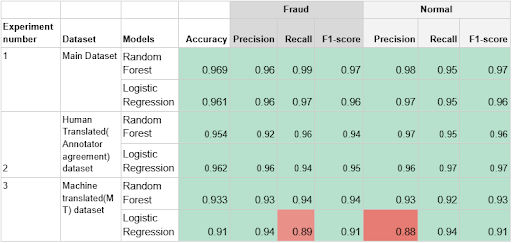
A table of machine learning experimental results
New large dataset
The research culminated in a model capable of detecting fraudulent SMS messages with a high degree of accuracy. A total of 15,229 raw SMS messages ,both fraudulent and non-fraudulent, were collected during the data collection exercise. This dataset is currently being prepared for analysis.
Reflections on the experience
This research was more than an academic pursuit; it was a profound learning experience that extended far beyond technical model building. It highlighted the critical role of interdisciplinary collaboration, particularly through engaging with community stakeholders during data collection. Their firsthand experiences and insights provided invaluable context, deepening our understanding of the nuances of SMS fraud in Chichewa. These interactions helped us identify the tactics used by fraudsters and the cultural or linguistic cues that often made these scams convincing, ultimately shaping our approach to designing feasible research methodology.
Additionally, this project reinforced the importance of ethical considerations when working with sensitive data. We prioritised data privacy and security, ensuring that all collected information was handled responsibly to protect participants' identities. These measures aligned with our commitment to maintaining trust and upholding ethical research standards.
Finally, this research emphasised the need for context-aware innovation. By incorporating insights from the communities directly affected by SMS fraud, we shaped an approach that was both practical and grounded in real-world experiences. This ensured that our model not only performed well technically but also addressed the problem in a way that could resonate with and benefit the people it was intended to serve if integrated into a broader solution.
Moving forward
The fight against SMS fraud is far from over. While our model provides a robust starting point, there’s ample room for improvement. Future work could include experimenting with large SMS datasets and other SMS features such as phone numbers, time etc on top of SMS body which was only the focus feature in our research. Additionally, the development of a standardized Chichewa corpus could significantly benefit not only fraud detection but also other NLP applications.
Conclusion
Our journey in detecting SMS fraud in Chichewa illustrates the transformative potential of machine learning when applied thoughtfully to local contexts. By addressing language-specific challenges, we can create solutions that are not only innovative but also impactful. This project stands as a testament to the power of technology to bridge gaps and solve pressing societal problems, one message at a time.